
www.nature.com/nature/journal/v518/n7540/full/nature14236.html
Preview meta tags from the www.nature.com website.
Linked Hostnames
31- 106 links towww.nature.com
- 31 links toscholar.google.com
- 20 links todoi.org
- 19 links toscholar.google.co.uk
- 19 links towww.ncbi.nlm.nih.gov
- 8 links towww.springernature.com
- 7 links tostatic-content.springer.com
- 4 links topartnerships.nature.com
Thumbnail
Search Engine Appearance
Human-level control through deep reinforcement learning - Nature
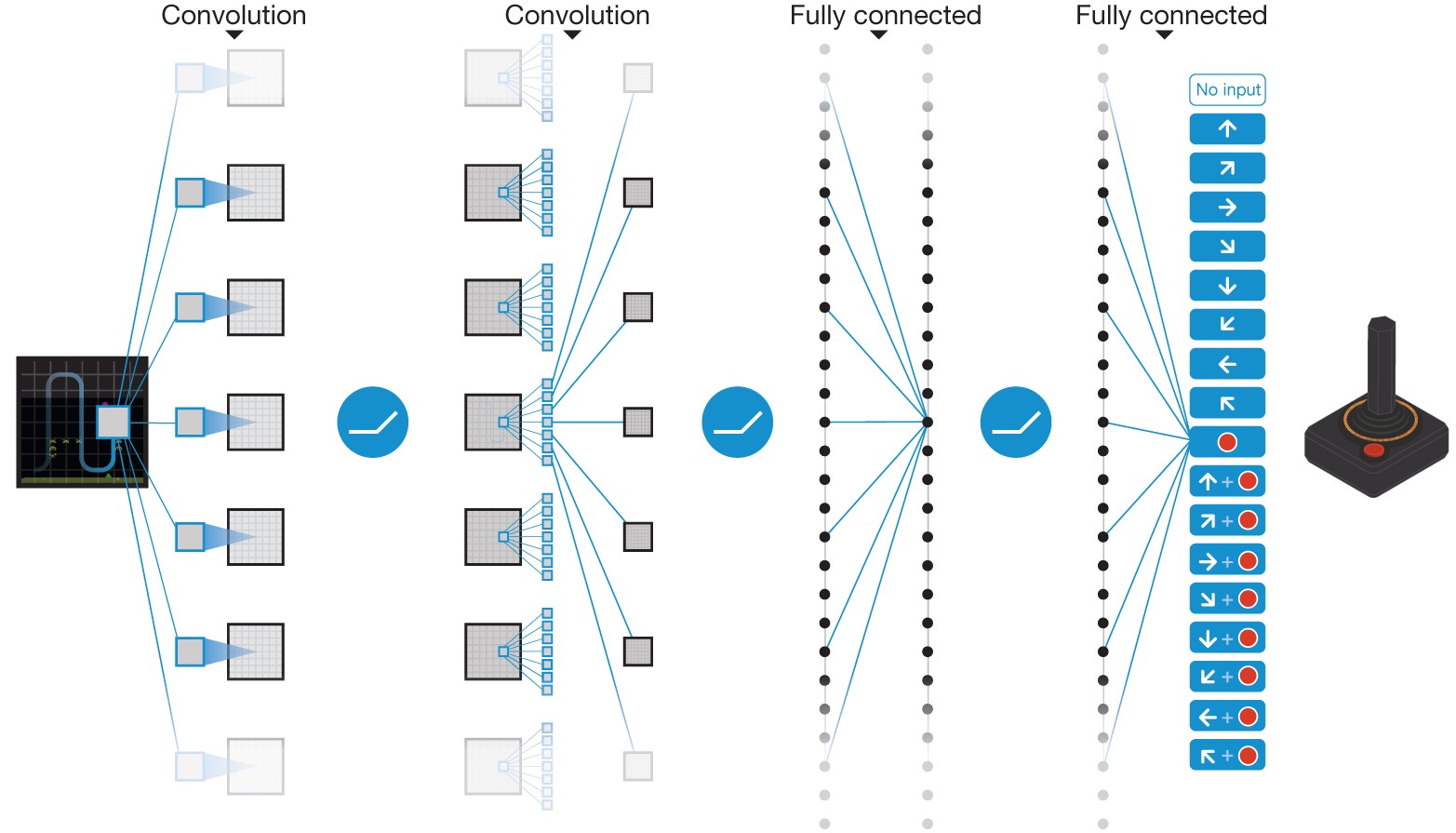
An artificial agent is developed that learns to play a diverse range of classic Atari 2600 computer games directly from sensory experience, achieving a performance comparable to that of an expert human player; this work paves the way to building general-purpose learning algorithms that bridge the divide between perception and action. For an artificial agent to be considered truly intelligent it needs to excel at a variety of tasks considered challenging for humans. To date, it has only been possible to create individual algorithms able to master a single discipline — for example, IBM's Deep Blue beat the human world champion at chess but was not able to do anything else. Now a team working at Google's DeepMind subsidiary has developed an artificial agent — dubbed a deep Q-network — that learns to play 49 classic Atari 2600 'arcade' games directly from sensory experience, achieving performance on a par with that of an expert human player. By combining reinforcement learning (selecting actions that maximize reward — in this case the game score) with deep learning (multilayered feature extraction from high-dimensional data — in this case the pixels), the game-playing agent takes artificial intelligence a step nearer the goal of systems capable of learning a diversity of challenging tasks from scratch. The theory of reinforcement learning provides a normative account1, deeply rooted in psychological2 and neuroscientific3 perspectives on animal behaviour, of how agents may optimize their control of an environment. To use reinforcement learning successfully in situations approaching real-world complexity, however, agents are confronted with a difficult task: they must derive efficient representations of the environment from high-dimensional sensory inputs, and use these to generalize past experience to new situations. Remarkably, humans and other animals seem to solve this problem through a harmonious combination of reinforcement learning and hierarchical sensory processing systems4,5, the former evidenced by a wealth of neural data revealing notable parallels between the phasic signals emitted by dopaminergic neurons and temporal difference reinforcement learning algorithms3. While reinforcement learning agents have achieved some successes in a variety of domains6,7,8, their applicability has previously been limited to domains in which useful features can be handcrafted, or to domains with fully observed, low-dimensional state spaces. Here we use recent advances in training deep neural networks9,10,11 to develop a novel artificial agent, termed a deep Q-network, that can learn successful policies directly from high-dimensional sensory inputs using end-to-end reinforcement learning. We tested this agent on the challenging domain of classic Atari 2600 games12. We demonstrate that the deep Q-network agent, receiving only the pixels and the game score as inputs, was able to surpass the performance of all previous algorithms and achieve a level comparable to that of a professional human games tester across a set of 49 games, using the same algorithm, network architecture and hyperparameters. This work bridges the divide between high-dimensional sensory inputs and actions, resulting in the first artificial agent that is capable of learning to excel at a diverse array of challenging tasks.
Bing
Human-level control through deep reinforcement learning - Nature
An artificial agent is developed that learns to play a diverse range of classic Atari 2600 computer games directly from sensory experience, achieving a performance comparable to that of an expert human player; this work paves the way to building general-purpose learning algorithms that bridge the divide between perception and action. For an artificial agent to be considered truly intelligent it needs to excel at a variety of tasks considered challenging for humans. To date, it has only been possible to create individual algorithms able to master a single discipline — for example, IBM's Deep Blue beat the human world champion at chess but was not able to do anything else. Now a team working at Google's DeepMind subsidiary has developed an artificial agent — dubbed a deep Q-network — that learns to play 49 classic Atari 2600 'arcade' games directly from sensory experience, achieving performance on a par with that of an expert human player. By combining reinforcement learning (selecting actions that maximize reward — in this case the game score) with deep learning (multilayered feature extraction from high-dimensional data — in this case the pixels), the game-playing agent takes artificial intelligence a step nearer the goal of systems capable of learning a diversity of challenging tasks from scratch. The theory of reinforcement learning provides a normative account1, deeply rooted in psychological2 and neuroscientific3 perspectives on animal behaviour, of how agents may optimize their control of an environment. To use reinforcement learning successfully in situations approaching real-world complexity, however, agents are confronted with a difficult task: they must derive efficient representations of the environment from high-dimensional sensory inputs, and use these to generalize past experience to new situations. Remarkably, humans and other animals seem to solve this problem through a harmonious combination of reinforcement learning and hierarchical sensory processing systems4,5, the former evidenced by a wealth of neural data revealing notable parallels between the phasic signals emitted by dopaminergic neurons and temporal difference reinforcement learning algorithms3. While reinforcement learning agents have achieved some successes in a variety of domains6,7,8, their applicability has previously been limited to domains in which useful features can be handcrafted, or to domains with fully observed, low-dimensional state spaces. Here we use recent advances in training deep neural networks9,10,11 to develop a novel artificial agent, termed a deep Q-network, that can learn successful policies directly from high-dimensional sensory inputs using end-to-end reinforcement learning. We tested this agent on the challenging domain of classic Atari 2600 games12. We demonstrate that the deep Q-network agent, receiving only the pixels and the game score as inputs, was able to surpass the performance of all previous algorithms and achieve a level comparable to that of a professional human games tester across a set of 49 games, using the same algorithm, network architecture and hyperparameters. This work bridges the divide between high-dimensional sensory inputs and actions, resulting in the first artificial agent that is capable of learning to excel at a diverse array of challenging tasks.
DuckDuckGo
https://www.nature.com/nature/journal/v518/n7540/full/nature14236.htmlHuman-level control through deep reinforcement learning - Nature
An artificial agent is developed that learns to play a diverse range of classic Atari 2600 computer games directly from sensory experience, achieving a performance comparable to that of an expert human player; this work paves the way to building general-purpose learning algorithms that bridge the divide between perception and action. For an artificial agent to be considered truly intelligent it needs to excel at a variety of tasks considered challenging for humans. To date, it has only been possible to create individual algorithms able to master a single discipline — for example, IBM's Deep Blue beat the human world champion at chess but was not able to do anything else. Now a team working at Google's DeepMind subsidiary has developed an artificial agent — dubbed a deep Q-network — that learns to play 49 classic Atari 2600 'arcade' games directly from sensory experience, achieving performance on a par with that of an expert human player. By combining reinforcement learning (selecting actions that maximize reward — in this case the game score) with deep learning (multilayered feature extraction from high-dimensional data — in this case the pixels), the game-playing agent takes artificial intelligence a step nearer the goal of systems capable of learning a diversity of challenging tasks from scratch. The theory of reinforcement learning provides a normative account1, deeply rooted in psychological2 and neuroscientific3 perspectives on animal behaviour, of how agents may optimize their control of an environment. To use reinforcement learning successfully in situations approaching real-world complexity, however, agents are confronted with a difficult task: they must derive efficient representations of the environment from high-dimensional sensory inputs, and use these to generalize past experience to new situations. Remarkably, humans and other animals seem to solve this problem through a harmonious combination of reinforcement learning and hierarchical sensory processing systems4,5, the former evidenced by a wealth of neural data revealing notable parallels between the phasic signals emitted by dopaminergic neurons and temporal difference reinforcement learning algorithms3. While reinforcement learning agents have achieved some successes in a variety of domains6,7,8, their applicability has previously been limited to domains in which useful features can be handcrafted, or to domains with fully observed, low-dimensional state spaces. Here we use recent advances in training deep neural networks9,10,11 to develop a novel artificial agent, termed a deep Q-network, that can learn successful policies directly from high-dimensional sensory inputs using end-to-end reinforcement learning. We tested this agent on the challenging domain of classic Atari 2600 games12. We demonstrate that the deep Q-network agent, receiving only the pixels and the game score as inputs, was able to surpass the performance of all previous algorithms and achieve a level comparable to that of a professional human games tester across a set of 49 games, using the same algorithm, network architecture and hyperparameters. This work bridges the divide between high-dimensional sensory inputs and actions, resulting in the first artificial agent that is capable of learning to excel at a diverse array of challenging tasks.
General Meta Tags
150- titleHuman-level control through deep reinforcement learning | Nature
- titleClose banner
- titleClose banner
- X-UA-CompatibleIE=edge
- applicable-devicepc,mobile
Open Graph Meta Tags
6- og:urlhttps://www.nature.com/articles/nature14236
- og:typearticle
- og:site_nameNature
- og:titleHuman-level control through deep reinforcement learning - Nature
- og:descriptionAn artificial agent is developed that learns to play a diverse range of classic Atari 2600 computer games directly from sensory experience, achieving a performance comparable to that of an expert human player; this work paves the way to building general-purpose learning algorithms that bridge the divide between perception and action.
Twitter Meta Tags
6- twitter:site@nature
- twitter:cardsummary_large_image
- twitter:image:altContent cover image
- twitter:titleHuman-level control through deep reinforcement learning
- twitter:descriptionNature - For an artificial agent to be considered truly intelligent it needs to excel at a variety of tasks considered challenging for humans. To date, it has only been possible to create...
Item Prop Meta Tags
4- position1
- position2
- position3
- publisherSpringer Nature
Link Tags
15- alternatehttps://www.nature.com/nature.rss
- apple-touch-icon/static/images/favicons/nature/apple-touch-icon-f39cb19454.png
- canonicalhttps://www.nature.com/articles/nature14236
- icon/static/images/favicons/nature/favicon-48x48-b52890008c.png
- icon/static/images/favicons/nature/favicon-32x32-3fe59ece92.png
Emails
2Links
249- http://adsabs.harvard.edu/cgi-bin/nph-data_query?link_type=ABSTRACT&bibcode=2002Natur.415..318S
- http://adsabs.harvard.edu/cgi-bin/nph-data_query?link_type=ABSTRACT&bibcode=2006Sci...313..504H
- http://scholar.google.com/scholar_lookup?&title=A%20neural%20substrate%20of%20prediction%20and%20reward&journal=Science&doi=10.1126%2Fscience.275.5306.1593&volume=275&pages=1593-1599&publication_year=1997&author=Schultz%2CW&author=Dayan%2CP&author=Montague%2CPR
- http://scholar.google.com/scholar_lookup?&title=An%20analysis%20of%20temporal-difference%20learning%20with%20function%20approximation&journal=IEEE%20Trans.%20Automat.%20Contr.&doi=10.1109%2F9.580874&volume=42&pages=674-690&publication_year=1997&author=Tsitsiklis%2CJ&author=Roy%2CBV
- http://scholar.google.com/scholar_lookup?&title=An%20object-oriented%20representation%20for%20efficient%20reinforcement%20learning&pages=240-247&publication_year=2008&author=Diuk%2CC&author=Cohen%2CA&author=Littman%2CML